
 Brooke Lark
Brooke LarkDie letzten drei Jahre Pandemie haben einen Trend beschleunigt, der bereits seit Jahren besteht: „Social Commerce“. Dieser Begriff bezeichnet den Erwerb von Produkten und Dienstleistungen über Plattformen wie Facebook, Instagram oder TikTok, teilweise ohne diese verlassen zu müssen. Diese Entwicklung bringt Marken dazu, sich im Bereich Social Media neu aufzustellen.
Die Corona-Zeit hat viele Menschen zu Social Shoppern gemacht: 43 Prozent aller in Deutschland lebenden Menschen haben bereits ein Produkt über ein soziales Netzwerk gekauft oder können sich vorstellen, dies künftig zu tun. Jeder Dritte der Gen Z oder Millennials nutzt soziale Medien bereits regelmäßig zum Einkaufen. Zwei Eigenschaften unterscheiden den Social Commerce dabei vom klassischen Onlinehandel:
- Produkte werden nicht gesucht, sondern gefunden: Oft weckt erst die Präsentation auf den Social-Media-Plattformen das Kaufbedürfnis.
- Influencer:innen spielen eine große Rolle bei der Kaufentscheidung: Diese wird bei Konsument:innen nicht ausschließlich durch die Präsentation der Produkte getroffen, sondern inspiriert vom Verhalten anderer User:innen.
Diese neue Art des “Inspirational Shoppings“ bedeutet für Marken, Social-Commerce-Systeme aufzubauen, die sich von klassischen E-Commerce-Mechaniken unterscheiden. Folgende fünf Punkte helfen Marken, sich im Dschungel der Möglichkeiten zu orientieren:#
1. Readiness-Check: Status Quo und Potential-Analyse
Die Bewertung des Status Quo in Bezug auf Datenquellen, technische Voraussetzungen und kreatives Potenzial der Marke bildet die Basis für einen erfolgreichen Einstieg im Social Commerce. Zunächst ist zu prüfen, ob die Unternehmenslandschaft die Anforderungen erfüllt. Folgende Fragen müssen sich Entscheider:innen dabei stellen: Eignet sich das Produkt oder die Dienstleistung für Social Commerce? Können Pixel und Co. implementiert werden, um möglichst viele Datenpunkte zu generieren? Welche Creatives und Inhalte sprechen die Zielgruppe an? Wie können Potenziale mit dem entsprechenden Budget effizient ausgeschöpft werden?
2. Zielgruppenfokus und Plattformwahl: Das „Wo“ ist entscheidend
Das entscheidende strategische Element in der Evaluierung der Social-Commerce-Taktik ist die Plattformwahl: Facebook beispielsweise bietet spannende Features wie Gruppen, Instagram und TikTok stehen bei der Gen Z und den Millennials hoch im Kurs. Pinterest ist dagegen eher Suchmaschine als Social-Media-Plattform und kann Traffic auf die eigenen Plattformen bringen. Snapchat und TikTok wiederum eröffnen im Bereich Live Shopping spannende Möglichkeiten. Welches die richtige Plattform ist, hängt also von Zielgruppe, Zielen und vom zu vermarktenden Produkt ab.
3. Nutzung von geeigneten Spielarten: Shoppable Posts, Influencer Marketing, Live Shopping u.v.m.
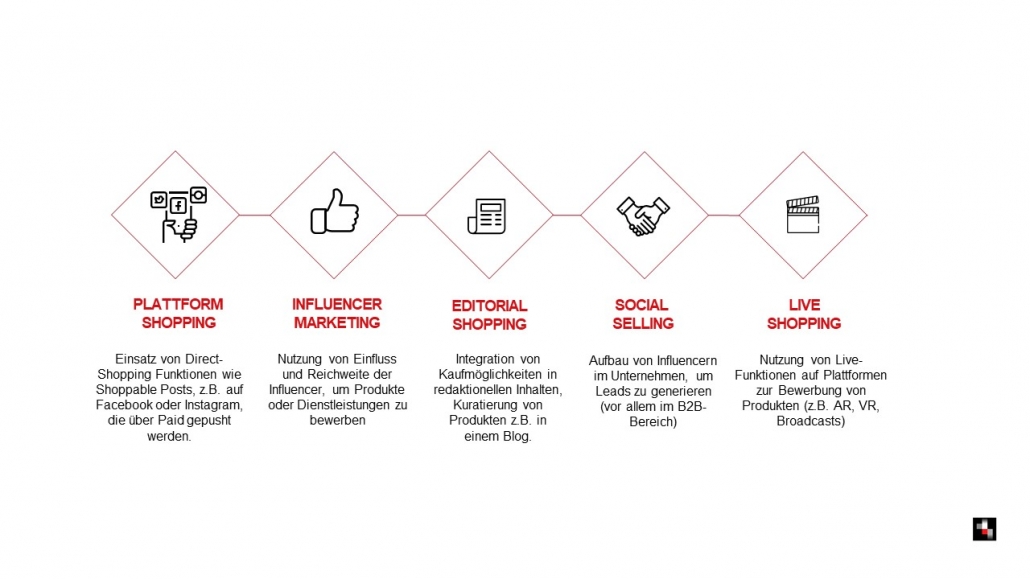
Neben direkten Kauf-Funktionalitäten wie Shoppable Ads oder Product Tags bieten die Social-Media-Plattformen aber noch eine Vielzahl an weiteren Spielarten, die eine gesamte potenzielle Shopping Journey abdecken: von der Produktentdeckung über Empfehlungen und Bewertungen, den Kauf an sich und die Zeit danach. Ein Beispiel hierfür ist der neue „Live-Shopping“-Trend, der sich in China bereits durchgesetzt hat: Brands können über Echtzeit-Events eine direkte und persönliche Verbindung zur Zielgruppe aufbauen, Empfehlungen geben, Fragen beantworten und Vertrauen schaffen.
4. Bezahlte Werbung: Steigerung der Reichweite und Messung der Conversions
Auch wenn Plattformen, Features und Inhalte optimal aufeinander abgestimmt sind, reicht die sogenannte „organische Reichweite“ heutzutage nicht mehr aus, um Inhalte zu verbreiten und Produkte zu vermarkten. Die gute Nachricht: Social-Media-Nutzer:innen befassen sich auf den Plattformen eher mit Werbeanzeigen als auf normalen Websites und neigen hier häufiger zu Impulskäufen. Die Plattformen bieten individuelle Lösungen in Sachen Formate und Targetings. Oft ist allerdings die Implementierung eines Pixels auf der eigenen Website notwendige Voraussetzung für die Sammlung von Datenpunkten sowie effizientes Tracking. Im Zuge des Readiness-Checks gehört eine datenschutzrechtliche Prüfung der Rahmenbedingungen daher ebenfalls dazu.
5. Community Management: Käuferbindung und Produktrezensionen 2.0
Durch den gezielten Aufbau einer direkten und persönlichen Beziehung zur Zielgruppe, beispielsweise durch Interaktion und Einbindung in Produktentwicklungen, können User:innen als wichtige Fürsprecher in der Kommunikation eingesetzt werden. 29 Prozent der Social Shopper empfehlen das über Social Media gekaufte Produkt in den sozialen Medien weiter. Empfehlungen durch User Generated Content sind besonders glaubwürdig und haben einen signifikanten Einfluss auf Kaufentscheidungen. Kritische Stimmen sind ebenfalls wertvoll und sollten nicht außer Acht gelassen werden. Sie können dazu dienen, das Produkt zu verbessern oder Nutzerbedürfnisse zu erkennen.
Es braucht eine langfristige Strategie für den Markenerfolg
Social Commerce ist
gekommen, um zu bleiben.Je nach Produkt, Dienstleistung
oder Branche kann das Zusammenspiel zwischen den genannten Bausteinen wie
Zielgruppe, Kanal, Story, Format, der Auf- und Ausbau der Community, die
Kooperation mit Influencer:innen sowie mediale Ausspielung ganz unterschiedlich
ausfallen – und dies ist sowohl kurzfristig, zum Beispiel in einer Testkampagne,
als auch in einer langfristigen Marketingplanung unbedingt zu berücksichtigen. Und
ein langer Atem lohnt: Zieht man die Prognosen zur inhaltlichen und technischen Entwicklung
der Social-Media-Plattformen heran, so bleibt Social Commerce kein kurzer Hype,
sondern ein Trend, der schon längst den Weg ins „New Normal“ gefunden hat.




 Foto von Tara Winstead von Pexels
Foto von Tara Winstead von Pexels
